How CryptoQuant is built
CryptoQuant is basically one person startup, hence, the architectural choices made need to be pragmatic.

I chose f# as a primary backend language, due to its compatibity with c# (and ability to use c# libraries). I am a dotnet guy, prefer strong typing to dynamic one, as I saw more than one project struggle with python due to its weakly typed nature when project grows and team expands.
F# has mathematically stronger typing and does not require user to annotate types everywhere. I feel like it's more flexible, adjustable, refactoring is easier than c#, at the same time giving even stronger typing than c# itself. Immutability by default makes writing code easier after time, and c# now feels ugly. Domain modelling with f# is more powerful (and beautiful) than with c# (or other OO languages), if you don't believe me, go see this talk by its designer.
For shorter argument in favour of f#, have a look at this article explaining how to make illegal states unrepresentable. This paradigm saves a lot of headaches later in the process and makes logic crystal clear.
I would say it's especially well suited for fintech domain. I will delve in f# more deeply in some other article as I think it deserves deeper evaluation and look.
Infrastructure
Hetzner dedicated server with docker compose. That's it, no other external (paid) services (except for payment processor and mail sender).
Monthly bill is under $100. I do not like spending time with administration, hence coreOS is immutable, auto-updatable and if update fails reversible into previous version. Probability this happens is low, as you cannot really install anything there (with some caveats) and it's made for running containers. Since all installs of the coreOS are the same, updates are much easier to test for its developers.
This also means, should something happen, moving to different server should be relatively fast (installation of coreOS is automated based on ignition file), and only containers need to be deployed.
I really like that it's not tied to api of any cloud provider. More than one developer shares this view. My wallet is also happy with that as I have seen bill of more than one startup from aws I worked for. Once you start using convenient services from them, it is very hard to stay cloud-provider agnostic.
This setup is also future-proof, as if more servers are needed, I just need to move to docker swarm (do not plan to overcomplicate with kubernetes). This entire saving and pattern is enabled by a cloud-native software architecture which works really well for future scaling this infrastructure.
Technology
In order to be able to scale seamlessly (horizontally/vertically), we need our docker containers (services) to communicate between each other.
For this particular project, I am using redis streams since I am already using redis anyway for caching. It is much easier to instantiate than kafka, although it is slower, but based on what I have read, many medium sized companies would benefit from lower complexity than e.g. kafka.
It is fast enough, append-only, supports consumer groups, acknowledgements, groups remember where they finished even after application restart, thus to a large extent replacing a need for kafka. I primarily use it for competing services (out of which only one can run), such as downloading price data. So then I can have e.g. 10 same docker containers, and have a guarantee only one of them will download prices.
Then I use postgres which has a lot of goodies, as json columns, or reliable job queues via SKIP LOCKED, and for basic user management, or instrument definitions, nothing beats it's reliability. Btw. I don't like ORMs too much, I believe in raw sql with dapper.
For time series data, I have looked at various technologies, such as quest db, timescale, but have settled on more general clickhouse. Apart from being columnar database which for this use-case is a necessity, it has a lot of other goodies. It has realtime materialized views (not related to postgres ones). It's almost as defining etl pipeline in database itself.
So you dump raw data and can have, for instance, hourly or daily aggregates which update with each insert. The advantage of this is that although clickhouse might not be faster than timeseries specialized databases, this feature alone allows you to skip quering a lot of data by having automatic live aggregates. And they are super nice, when random joe suggests a missing feature if it is reasonable.
For migrations, if you have not used flyway, do yourself a favor and check it out. It supports both clickhouse and postgres, (and other major databases). The core thing is that you can write migrations in raw sql and it supports transactional migrations where it makes sense (so not for clickhouse which is not transactional).
On frontend I came to like angular, as opposed to react or svelte, which are fast to start with, but when things start getting more complex, the progress slows down a lot. I think they feel more like python (just on frontend). Angular has a lot of useful features built in, such as singleton services being shared among components (useful for sharing fetched data, or a state).
I have not yet encountered a need to manage state in any other way than by using services. Upgrades are also very reasonable and things do not break with major versions. Mainly because angular does not require a lot of external dependencies, and there is a lot of cohesion the angular team puts into libraries which are released together. I also like material components and its tight integration with angular.
It's definitely more batteries included approach compared to other frontend frameworks.
The advantage of using dotnet on backend is signalR, higher abstraction on top of websocket, which handles a lot of low level issues and brings live updates to life.
Authentication can be tricky, yet, we don't need to make this too complex. I will write a focused article on how I do that, but basically I am not using any external services, and I use secure cookies. They also work nicely with signalR, although stream needs to be restarted if user logs out/in, since it's a long lived connection.
For stripe payment gateway integration, I am thankful to this guide, so I share a link as it might help someone else as well.
For transactional e-mails I use mailgun, which has a reasonable setup process and a free tier for up to 2,000 e-mails/month.
Software
What I like to do is a monolith. Microservices are very popular, but for a SaaS app with less than 50 developers (or 40?) it's more sensible to go with a well written monolith.
Even though it's a monolith, you can always scale it (if you write it in a cloud-friendly way). You just need to be aware for each service inside a monolith, if it needs to be run as singleton, or you want to scale it with each instance running. And then with tools I mentioned above redis streams, postgres skip locked, redis distributed locks, postgres advisory locks you can guarantee a singleton easily across running instances of the monolith.
I myself focus on dotnet which has come a long way and runs natively in linux and is one of the fastest server technologies out there.
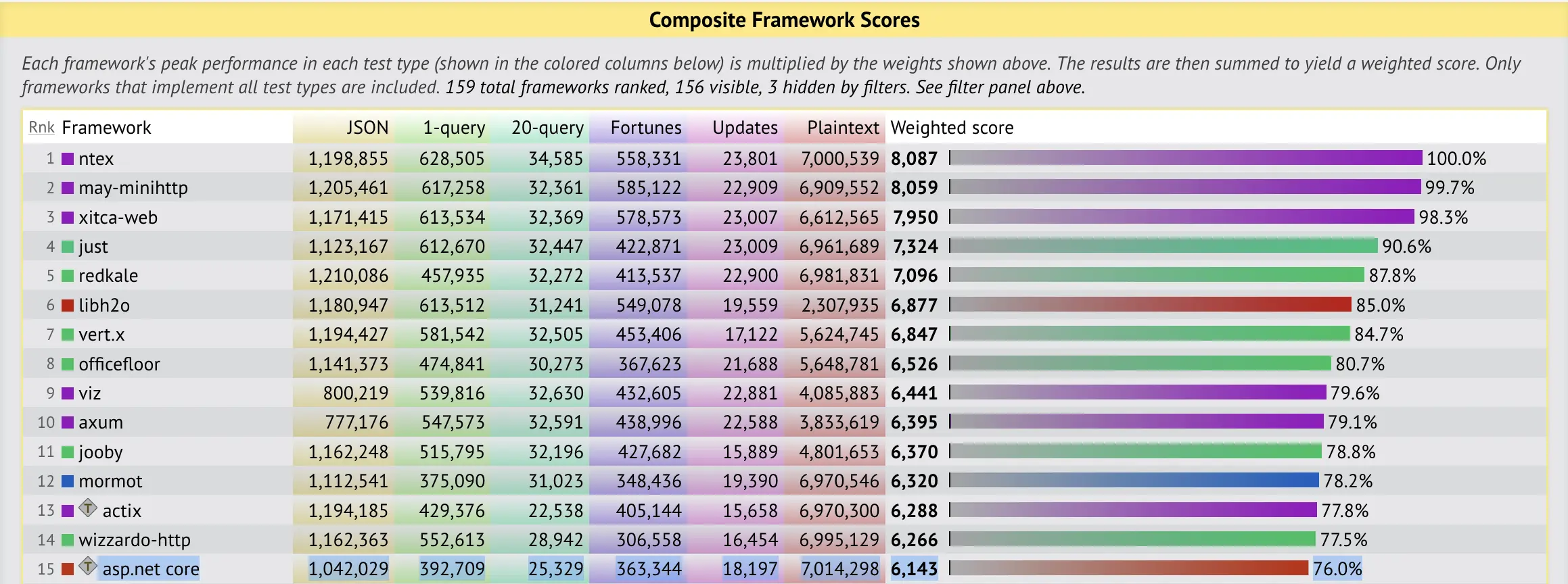
Asp.net core stands at 76%, django stands at around 5%, java spring at 18% and go gin at 20%.
I believe the platform choice is very important, there are some other interesting technologies from developer experience perspective such as clojure or elixir that I might explore at some point in the future.
Here is a simplified overview of major services, to have a better idea how processes are coordinated. We have a timer in every instance of our service, which fires every minute. Only single instance of service is able to acquire a lock, hence only one instance downloads prices. Once prices are downloaded, the rest of the workflow is communicated via redis stream as a consumer group, so only one calculates statistics, etc. The shift to concurrent model happens with postgres job queue, as all service instances run live jobs until jobs are exhausted.